The topic for this panel is "large news systems". I am Nick Christenson and two months ago I was the Senior Architect at EarthLink Network where I helped design the large scale email and news systems at this large, rapidly growing Internet Service Provider. The discriminating listener may notice that this talk bears a striking resemblance to a paper we wrote which was published in the June 1997 issue of ;login: magazine. Hopefully there are going to be enough information here so that if you've already read the paper, this won't be a complete waste of your time. In any case I hope this generates some good questions. And yes, I am unaffiliated, and not looking terribly seriously at this time but I always keep my ear to the ground looking for good opportunities.
In my mind, there are four ways you can go if you've got a news system and you want to make it really big. I envision a scenario where you've got a machine, maybe a desk top machine, that you've been able to scrounge for this purpose, you've also got some disk attached to it, and it's doing news. All of a sudden, Usenet volume goes up, the number of people at your company goes up, the amount of people reading news goes up, and pretty soon the system that you've created is now inadequate to the task. People are calling in and complaining about it being slow, you find your news feeds are backed up down the road, and expires are taking longer and longer. Well what do you do?
I'm also going to make an assumption that Usenet news at your company has at least some sort of institutional support. That is, it is somebody's job to do this and there is some gear that has been allocated for this task. Now, if this isn't the case, and it's very likely not to be the case, and this was certainly the way it was for me when I was at the Jet Propulsion Laboratory prior to working at EarthLink, where all the gear and time I was able to maintain news with was completely scrounged and I got by trading away favors. If that's the case and you're running out of bandwidth on your news system, you're just kinda out of luck, and all these cute ways you can go about making news perform better aren't going to do you a whole lot of good. Therefore, I'm going to make the assumption that there could be some resources available, at least potentially, even if you have to sell it as a research project.
Anyways, the first way you can go about increasing the capacity of your current news system is to get a bigger box, obviously. Frankly, this is one option that should not be pooh-poohed or set aside lightly. Odds are, of all the suggestions I'm going to mention, this is very likely the cheapest way to make your news system bigger in terms of the "cosmic economy." There probably isn't a system administrator in this room who doesn't have horrible demands placed on their time. System administrator salaries, fortunately for all of us, have been going up dramatically in the last couple of years, and having people implement fancy solutions making a Usenet News, or any other system, larger or run better is very expensive. It may be a heckuva lot cheaper to go out and buy a big box.
The next thing you can do, and this is another fairly obvious thing, is to split the load between multiple machines. You've got machine A, and it's overloaded, so create machine B, make it identical to machine A, and tell half the people (or use round robin DNS or something like that) to split the load over it. You can worry about keeping them in sync as master-slave, or just completely ignore that, and say, "Pick one of the two machines to use, and if you switch, your .newsrc file is going to bet messed up."
Once again, this isn't a horribly bad way to do it. It's main disadvantage is that now you've got two, I'm going to assume you're running INN, although that's not necessarily the case in this day and age, you've got two news server INN-like processes to maintain, and even though you set set them up and do a good job, these things run into problems every so often, and they run into problems more and more often these days as INN is getting pushed beyond the realm it was expected to operate in when it was originally written, and that takes time and costs money. If your management doesn't understand why this is a problem, you might want to think about, via some form or fashion, getting different management, but that's a whole different topic. There are many ways to go about doing that, I might add, but that's beyond the scope of what I'm talking about here.
The other thing you can do is go and try some sort of fancy software solution. There are solutions like Cyclone from the High Wind guys. Nice piece of software and not terribly expensive in the great scheme of things. It's still going to take some time--and that means money--to understand it, install it, test it, and all that sort of stuff. But not a bad idea.
A gentleman I went to school with, Scott Fritchie, wrote some patches to modify INN to store articles in what he calls the Cyclic News File System. If you were at this year's LISA you may have heard his paper on that. Cute Idea. This is one way you can go. Again, it's got some upsides. The big upside is you don't need to change hardware to get some performance back. A big downside is that it tends to be a sort of incremental improvement, maybe it gets you a 20 or 30% improvement, and that's not chicken feed, but after that what do you do if you need to make it a lot bigger.
What I'm going to talk about is what we described in our paper, and that's a truly distributed system. In some ways, this is the most expensive of these systems, and, quite honestly, unless you work for a big ISP or a very, very large corporation that's gobbling up a lot of other corporations as fast as they can and trying to centralize their news service (nobody would happen to know any places like that, would they?). Anyway, unless you're doing something like that this probably isn't going to be cost effective for you. Nonetheless, hopefully you'll find what I'm saying at least informative, and if not informative, at least mildly amusing.
One thing that shouldn't be overlooked is that to do news well these days is getting really, really difficult. The economic argument could well be to farm the task out to your Internet Service Provider. That's not something that may of us like to do, or that I like to do, because, frankly, I enjoy running a news server, but in a strict economic sense it may be the most viable thing to do, especially once you hit a hardware barrier.
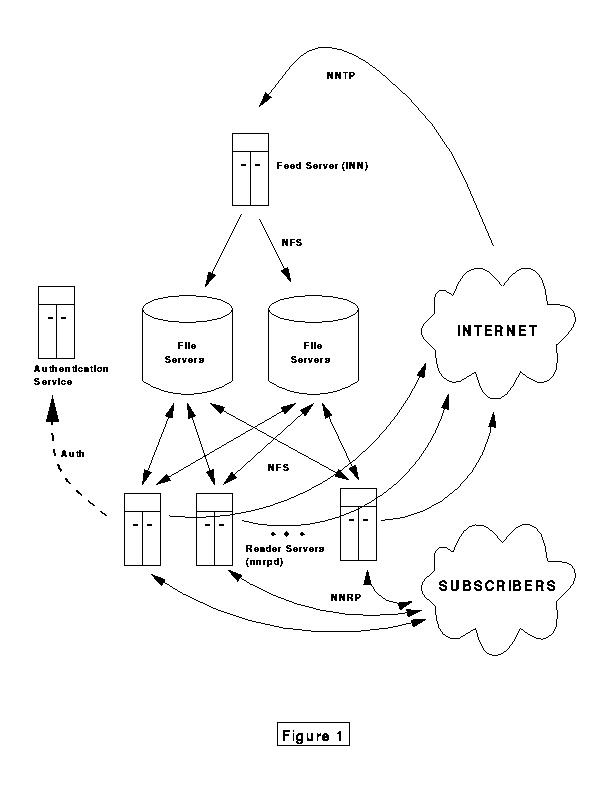
This is a basic block diagram of the news service at EarthLink, current as of the time that I left. I don't know that it looks the same now, but I suspect that it's pretty similar. In any case, the whole idea is that you've got one machine sitting up at the top here (labeled "Feed Server), and it's the only machine in the whole architecture running INN. What it's doing is writing the incoming feed to high performance file servers via NFS. And, yes, everyone should have a shocked look on their faces, I'm surprised I didn't hear a sharp intake of breath, because someone suggested the insane notion of running news over NFS. It is a crazy thing to do, but if you do it right it can actually work out fairly well. I'm going to describe in more detail some of the caveats a little later.
You've got a bunch of machines (labeled "Reader Servers") in Round Robin DNS. These machines run nnrpd out of the inetd.conf file and forward all the articles that get posted as a news feed to the INN machine. The feeder machine considers the nnrpd machines to be news feeds, so what happens is: the subscribers connect, in EarthLink's case to news.earthlink.net, round robin DNS assigns them one of these machines, they read, pulling news off the file servers over NFS, and post to these (nnrpd) machines. These machines do not write to the news spool, instead they forward the articles back up to the feeder machine which then writes the article to the spool and sends the article over the Internet to its upstream feeds. In fact, these machines mount the file servers read only which gives you two benefits:
In order to get the benefits of this system, you have to do a little modification of nnrpd, and only nnrpd really. There's some tuning stuff you might want to do to INN, most of this is done in the configuration file, data.conf when you're building it, but I'll talk about the modification of nnrpd in a minute.
In storing the articles over NFS, you're file server should be fast and allow you to do write asynchronously to it. That is, it should have battery backed memory where all the writes are stored, and it should also respond gracefully to load, if you want to scale the system.
EarthLink uses a switched FDDI fabric. This is something that I didn't think would work very well, but worked a lot better than I thought it would. Switched FDDI rubbed me the wrong way but it actually does a nice job. As a result of a fast file server performing asynchronous writes and a fast, uncongested network, you're talking about speeds and latencies over the NFS mounts that are actually approaching the channel speeds that you're getting from SCSI. Yes, you've got the The overhead involved in the TCP/IP stack, and the UDP layer, and the RPC layer, but they aren't as bad as you might at first think. And, so this actually works.
The other thing that happens, and you can see that in the diagram, is that nothing is preventing you from splitting the load across multiple file servers. And, in fact, you can go arbitrarily large only up to the limit of the number of file servers you feel comfortable with. So that, again, allows essentially arbitrary scalability in the file system area.
One machine, and only one machine, runs INN, which is your highest maintenance process. This means that you've really only got one machine to keep track of, because the nnrpd servers just don't have that much that can go wrong with them. Occasionally, you'll run into memory thrashing problems, or the machine can run out of control. Machines just do that, and they need to be dealt with, which is why we get the big bucks. But, you've only got one high maintenance machine to take care of and that's extremely valuable.
One of the things that's really important about the file servers in terms of efficient article storage is that FFS (the Berkeley Fast File System, the basis for most standard Unix file systems today) based file systems are just not very good for storing news because you've got the linear lookup of all of the nodes in the directory when you're looking for a file in the directory. So, you've got 10,000 articles/day coming into misc.jobs.offered, in fact that's old, I don't know how many are coming in these days, maybe its 15,000 or so, I wouldn't be surprised if this were the case. And any time you want to look up attribute information on any one of them you need to scan linearly through the directory. That's really bad. It's really much better to be able to scan for the file using a hashed directory lookup like you have in the XFS file system that SGI uses, the Veritas file system that you can buy for Sun, HP, and other platforms, or in our case, what we did was use the WAFL file system on the Network Appliance file servers.
You can use Round Robin DNS to balance the load on the nnrpd machines, this also gives you another great advantage. If one of them, for whatever reason, should happen to blow out a board, or cosmic rays hit it, or whatever happens, there's a simple remedy. All you do is remove it from the Round Robin, and you don't even have to repair it right away, if you've got N+1 redundancy, that is one extra nnrpd machine. This is really very nice. Everyone who was connected to the failed machine, boom, they get kicked off, they reconnect, they get a new address from the round robin DNS, and they don't really care. Of course all the machines are completely synched up because the active and history files are kept in common. So, one machine blows up, take it out of Round Robin DNS, then the system administrators can be instructed to go look for other problems and ignore the failed machine. It can be repaired, essentially, at your leisure. To be able to do that, especially in an ISP type environment, is incredibly valuable, to not have to fix something as soon as it's broken. Any time you're able to incorporate an N+1 redundant system you've got the advantages of good cost effectiveness along with extremely high robustness, and a big design goal of ours was to incorporate that everywhere we possibly could.
So, the good points of this system are:
There are some bad points:
One thing I need to mention and didn't mention, is that these nnrpd machines have another feature that's really important in terms of the scalability. That is if an article is posted and the nnrpd machine cannot feed it ahead to the feeder machine, it is stored in a separate NFS mounted space, and then rnews periodically tries to send it to the feeder. This is really important in case the feeder machine needs to be taken off line for whatever reason. INN, sometimes it's going to break. Or, if you need to add another file server, so what you do is put the new file server in service, shut down INN, start copying whatever portion of the spool is going to be copied over. In the mean time, the nnrpd machines are still mounting the news spool, users can still read news, and because of this feature, they can still post. Once the remounting occurs and the nnrpd machines are rebooted, which is necessary to get them to have their new view of the aggregate file system, then, boom, all the pent up postings are propagated back up to the feeder. So even when you're doing major, major maintenance on the virtual file system, everyone can still read news, and everyone can still post news. The only downside is that the postings are not propagated to the Internet right away. I think that's pretty good to be able to do that even when you're doing major surgery on the news spool.
As I indicated earlier, you can see this is one of the things that's going to be a problem if you have to start doing these file system moves more and more frequently. Then you're going to have more and more of these times when postings aren't being propagated and eventually people are going to get upset.
There are a couple of other features that have been incorporated into this system. One is the anti-spam exponential backoff in the nnrp daemon, that is, it looks at posting rates and if the posting rates exceed some threshold over a period of time, it starts accepting the postings after calling sleep() with a slowly growing argument. It's been carefully tuned so that no matter how fast you carry on a flame war, and, yes, this was tested in battle, posting by hand, you cannot detect the exponential backoff. At the same time, if a robot poster starts posting it's going to detect this and the backoff will kick in right away and the robot will slow down a great deal very quickly, which gets the spammers upset. And, frankly, I enjoy it when the spammers get upset.
EarthLink has separated it's authentication database. It's a fairly easy thing to modify nnrpd so that it does not look in the passwd file, or nnrpd.access file for authentication information, but instead goes over the network to a SQL database that has the authentication information in it. Then you can have an authenticating news server that will allow folks to use the news service from arbitrary points on the Internet. It's also allows you to have a machine for use by the legitimate roboposters, because you're carefully keeping track of who is posting and when. I already mentioned the store and forward feature on the nnrpd machines, in case the INN machine is down.
There are a couple of additional things that you can do. EarthLink may or may not have already implemented some of these ideas.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}